
Apache Kylin is a data cube solution on top of Hadoop providing an ODBC interface for BI tools.
OLAP cubes boosts performance for analytics via using a subset of data, enriched with pre-calculations on specific dimensions of interest.
It enables loading dimensions from a Hive data source, therefore accelerating BI tool access via pre-calculating data and adding it to HBase.
In our example we have a large dataset of flight information:
- Daily data of flights from an origin to a destination with expected and actual flight times
- Additional metadata is available on operators, cancellations, diverts, etc.
The goal of the experiment was to install Kylin, load a subset of our couple of gigabytes worth flight data and connect it to Microsoft PowerBI.
Kylin Pros and Cons
Pros
- Fast performance
- Easy to use UI
- ODBC connection to conventional BI tools
- Free and open-source tool integrating to the Hadoop eco-system
Cons
- A cube is pre-constructed, therefore provides access to a data snapshot. It should be re-built in case of updates and built differently in case of changes in dimensions or measures
- Kylin sometimes failed to build a cube or exited during the experiment
Experiment – POC with Kylin
Platform
- 8 core VM with 16 GBs of RAM
- CentOS 6.7
- HDP 2.5
- Kylin 1.5.4.1
- Hive has flight data loaded for each months of 2015 downloadable from the Bureau of Transportation Statictics
Data of interest
We are interested in the average delays on a month of a day and on a carrier basis.
In cube terms, dimensions categorizes facts for the users’ business questions.
E.g. for flights we are interested in a daily distribution of delays, so we select the day of the month or interested in an average delay per carrier, so we select carrier as dimensions.
A measure is a property for the calculation, so in our example is the delay in minutes.
Installing Kylin
Is easy – assuming Hive and HBase is working properly,
- Download Kylin
- tar xzvf kylin.tar.gz
- export KYLIN_HOME=(UntarredFolder)
- cd $KYLIN_HOME && ./bin/kylin.sh start
Kylin logs to $KYLIN_HOME/logs/kylin.log
Using Kylin to create cubes
Access Kylin via web browser at http://hadoopIP:7070/kylin, user ADMIN and password KYLIN
Unfortunately Kylin’s docs on cube creation is outdated -? as the interface looks a bit different, than the documentation.
How to create a cube with Kylin – Step by step screenshots
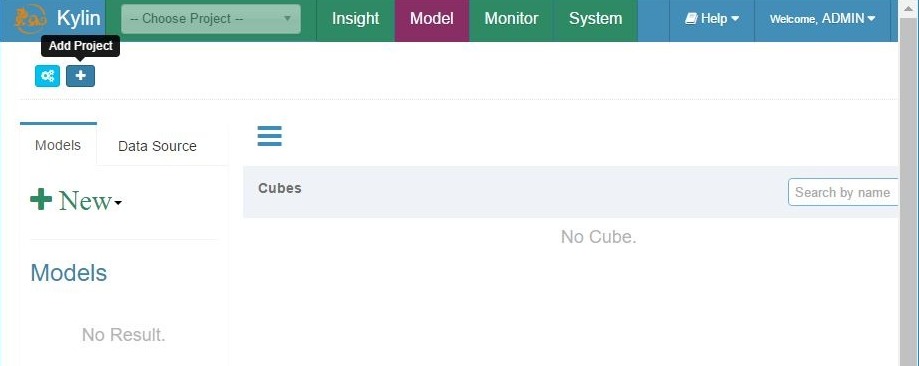
Add project
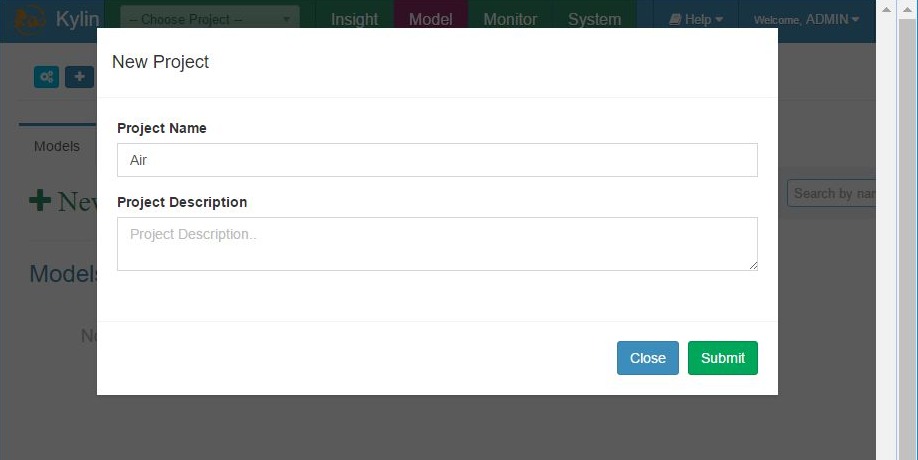
Add project – project properties
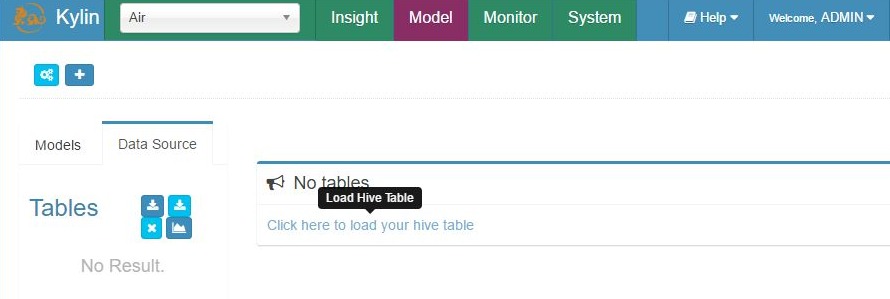
Load Hive source table – step 1
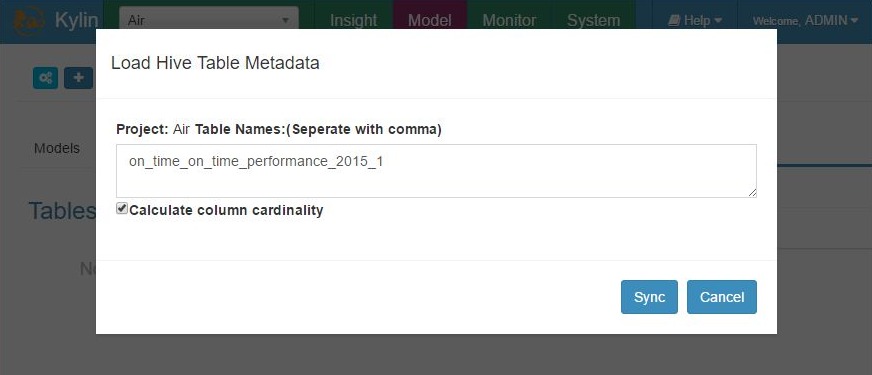
Load Hive source table – step 2
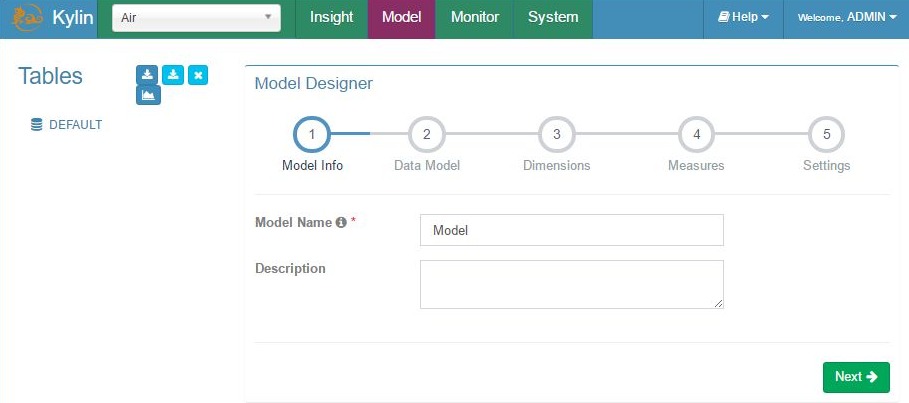
Add model – step 1, model info
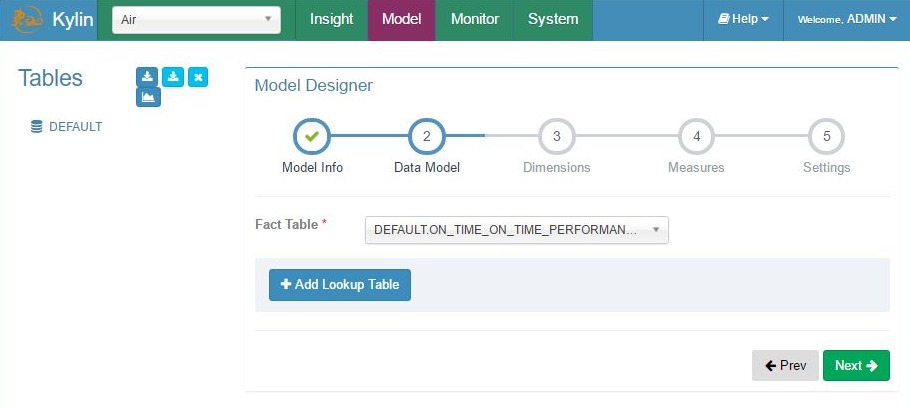
Add model – step 2, fact table (added from Hive)
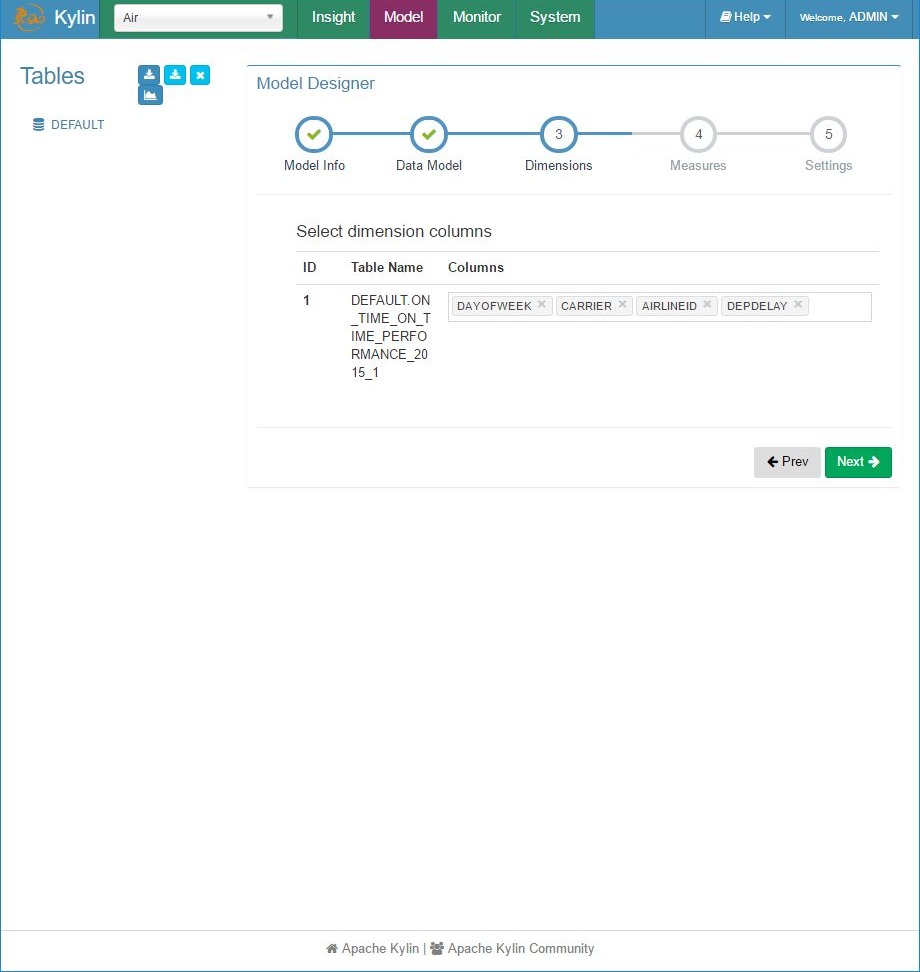
Add model – step 3, dimensions
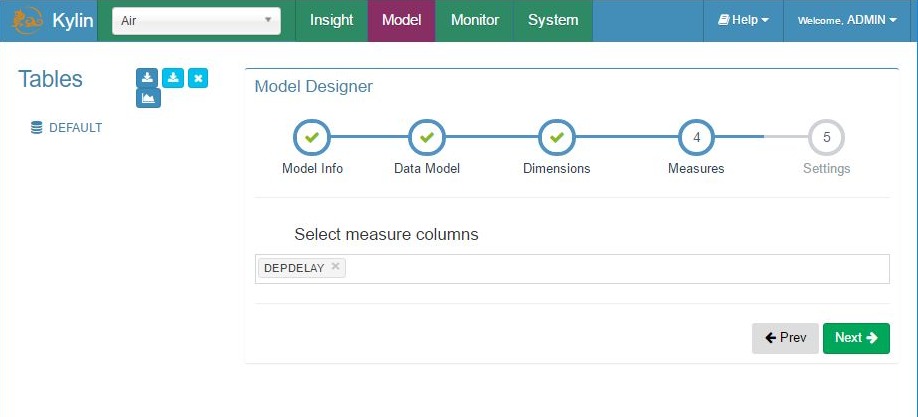
Add model – step 4, measures
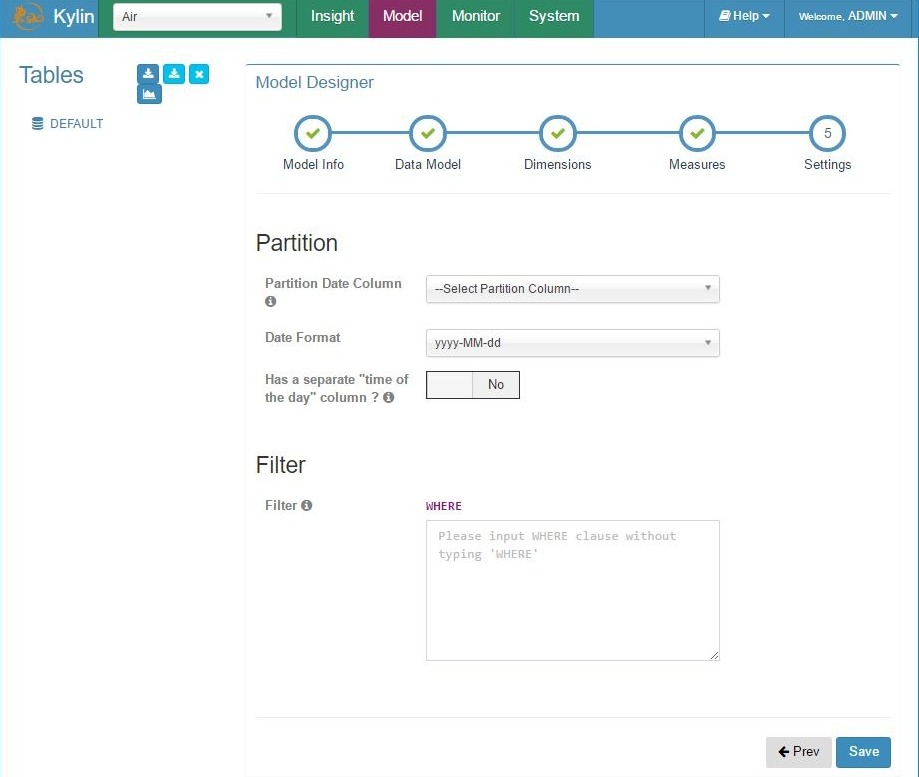
Add model – step 5, settings, partitioning
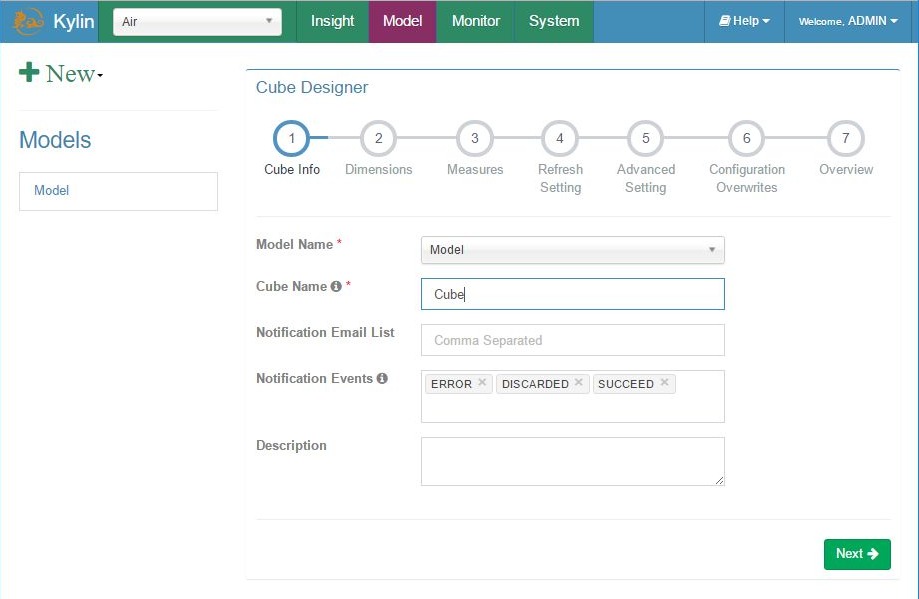
Add cube – step 1, cube info
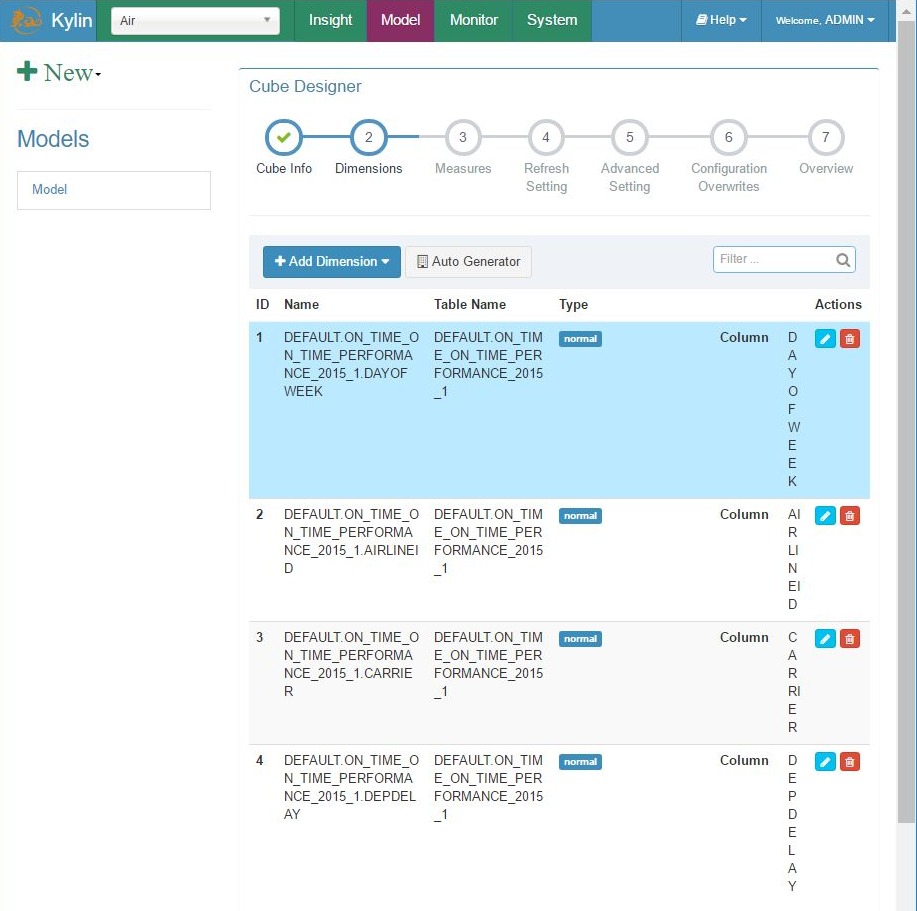
Add cube – step 2, dimensions info
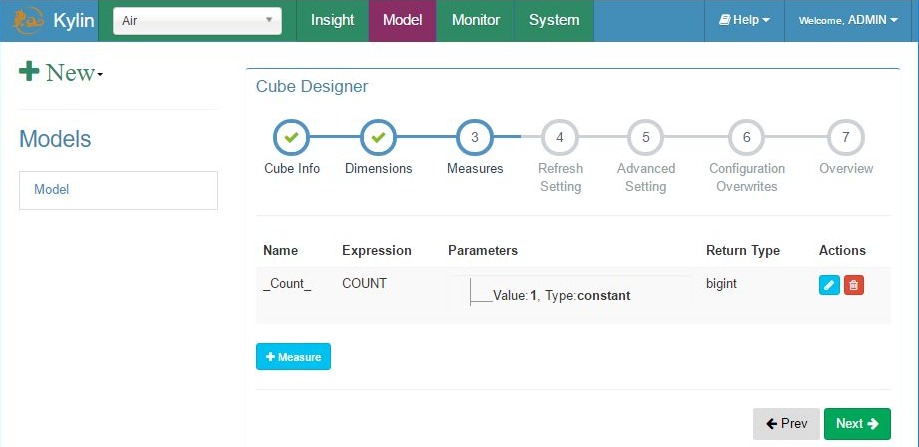
Add cube – step 3, measures info
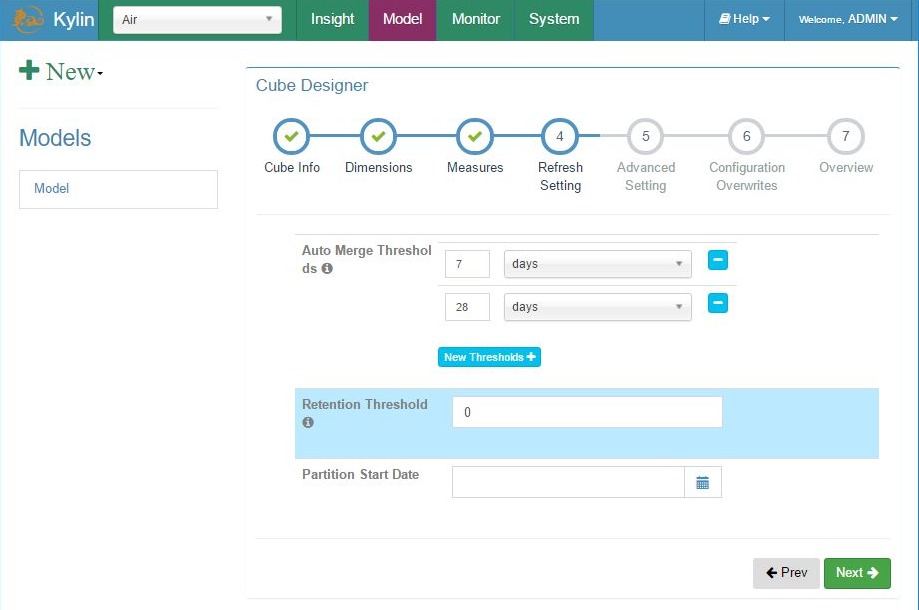
Add cube – step 4, cube auto refresh settings
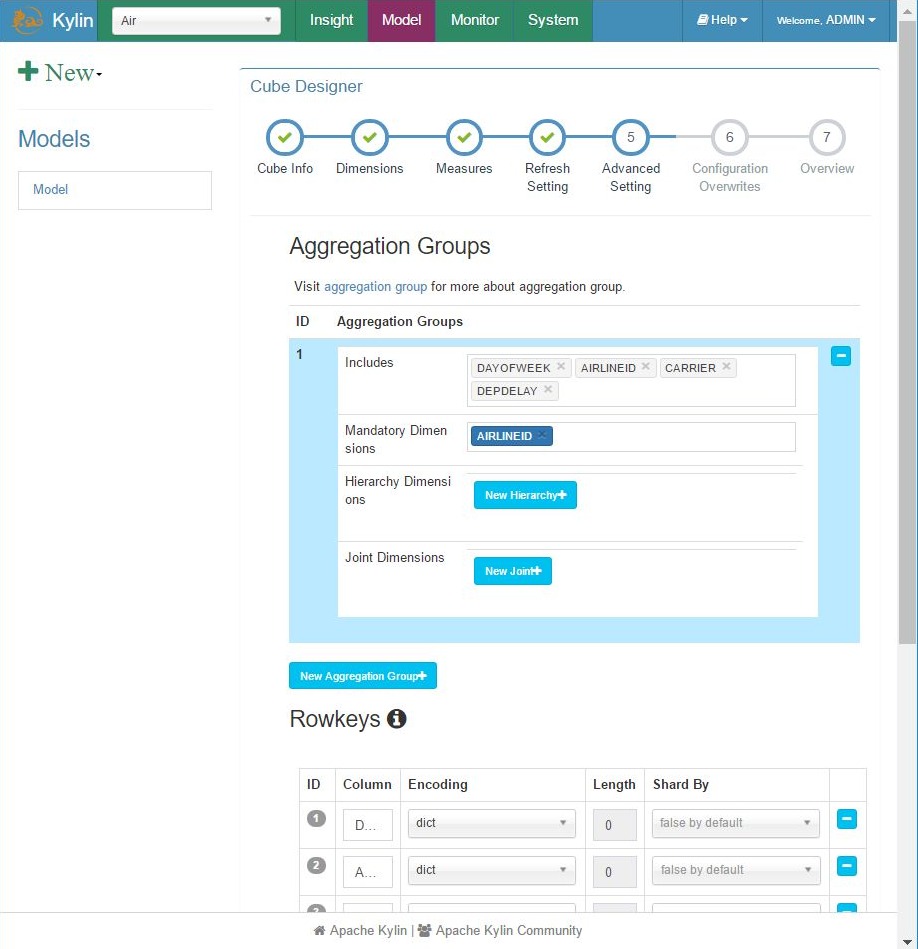
Add cube – step 5, aggregation groups
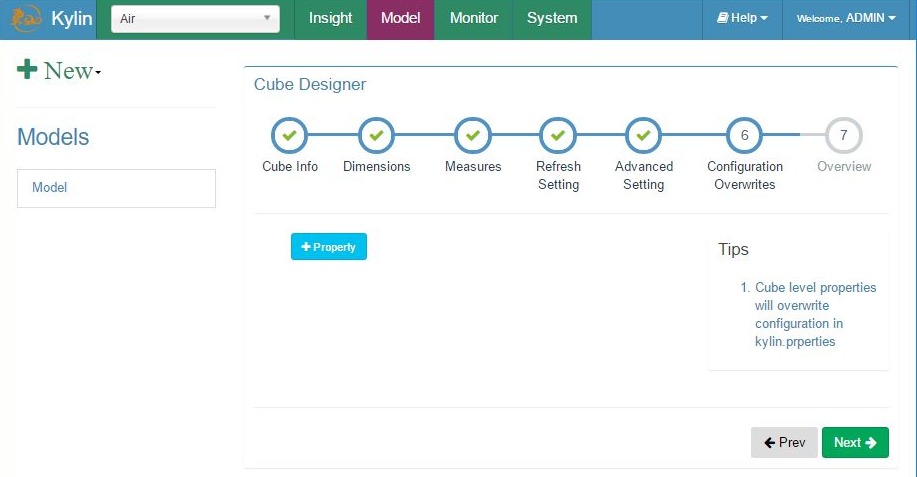
Add cube – step 6, manual configuration parameters
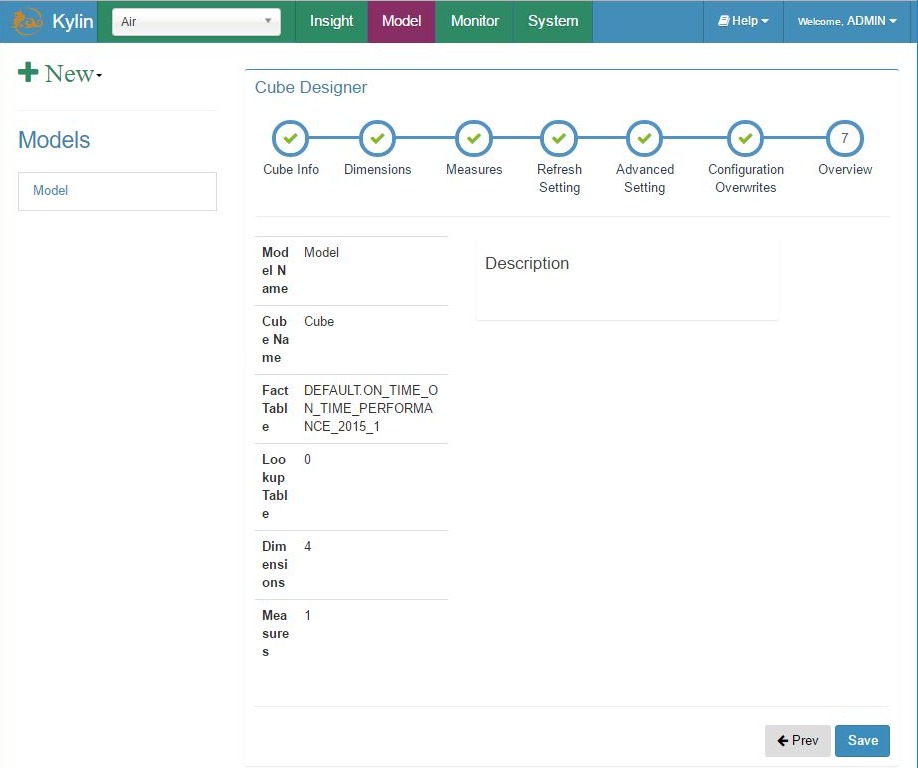
Add cube – step 7, overview, save
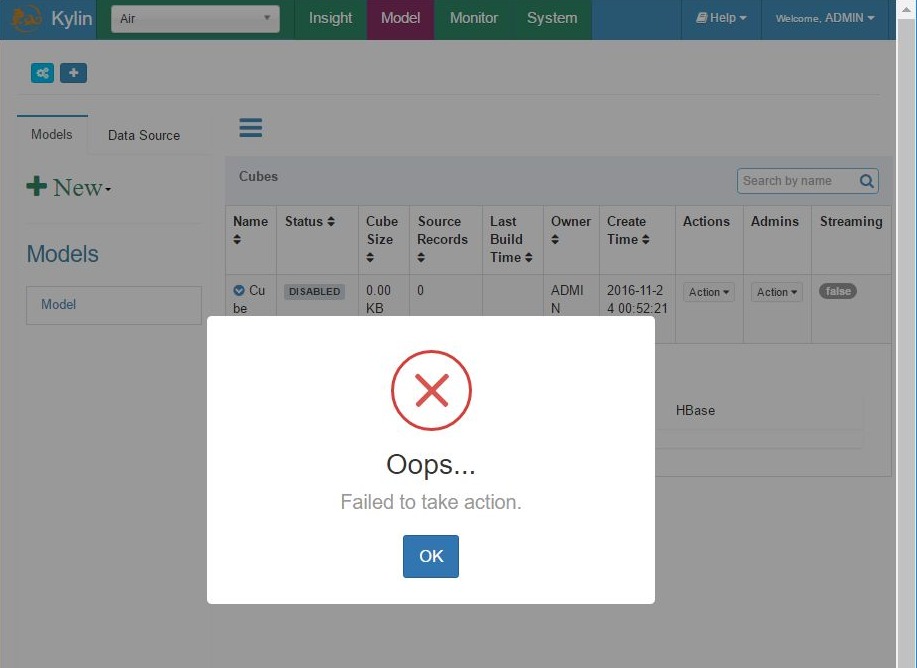
Add cube – stability issues arrise
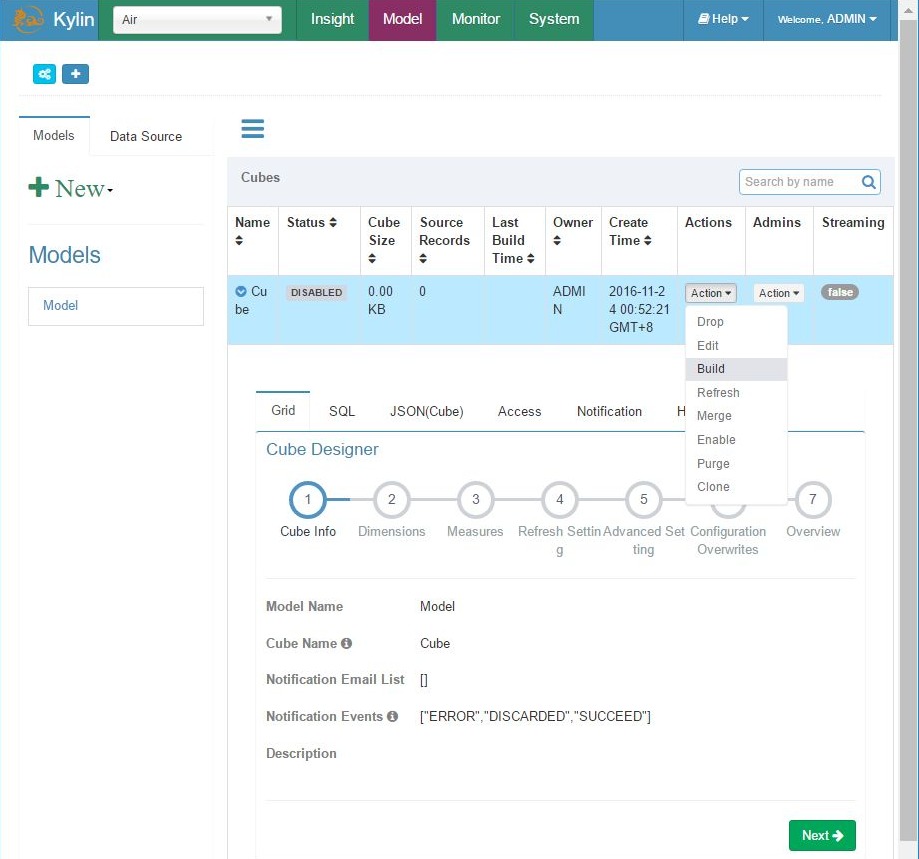
System monitor – schedule cube building
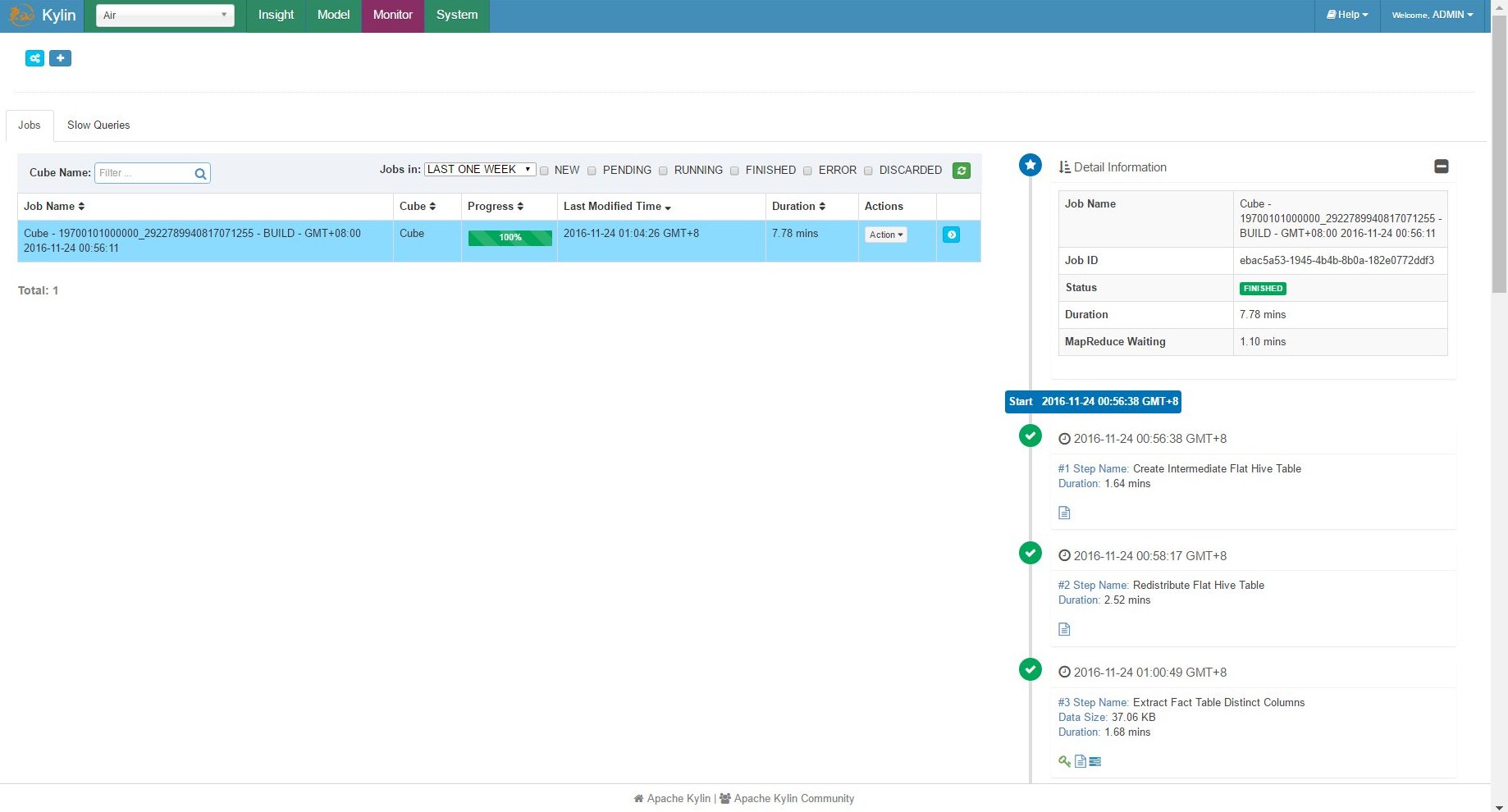
Cube building finished
Constructing the cube took 7.78 minutes.
Apache Kylin vs Apache Hive query performance
Hive
AVG delay on specific months of a day
AVG delay on specific months of a day SELECT DAYOFWEEK, AVG(DEPDELAY) FROM ON_TIME_PERFORMANCE_2015_1 GROUP BY DAYOFWEEK;
82.31 sec
AVG delay per carrier
AVG delay on specific months of a day SELECT DAYOFWEEK, AVG(DEPDELAY) FROM ON_TIME_PERFORMANCE_2015_1 GROUP BY DAYOFWEEK;
142.73 sec
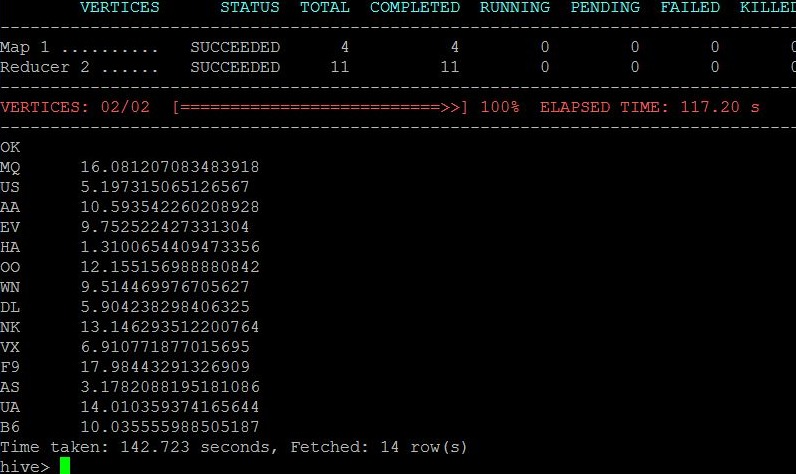
Hive query execution
Kylin
AVG delay on specific months of a day
AVG delay on specific months of a day SELECT DAYOFWEEK, AVG(DEPDELAY) FROM ON_TIME_PERFORMANCE_2015_1 GROUP BY DAYOFWEEK;
0.18 sec
AVG delay per carrier
AVG delay on specific months of a day SELECT DAYOFWEEK, AVG(DEPDELAY) FROM ON_TIME_PERFORMANCE_2015_1 GROUP BY DAYOFWEEK;
0.36 sec
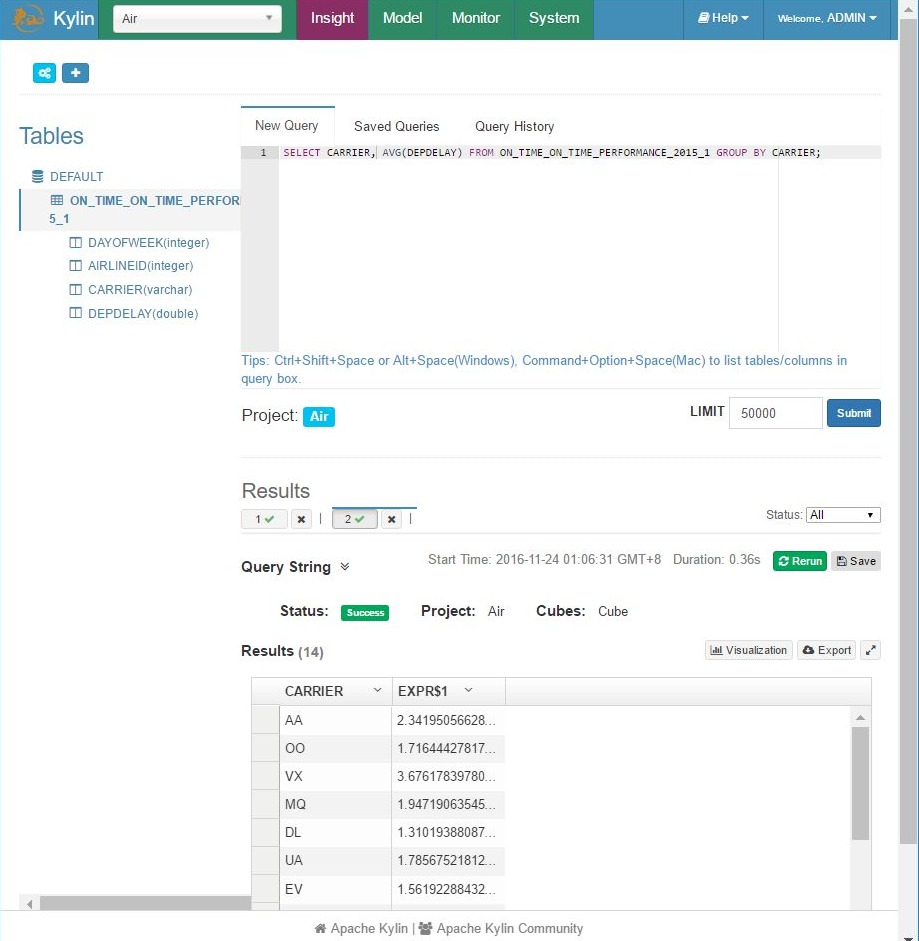
Kylin query execution